






 El análisis de sentimientos en la red social depende de cómo se expresan en palabras los estados mentales. Ahora una nueva base de datos de las relaciones entre palabras y emociones podría darnos un punto de partida mejor para este tipo de análisis.
El análisis de sentimientos en la red social depende de cómo se expresan en palabras los estados mentales. Ahora una nueva base de datos de las relaciones entre palabras y emociones podría darnos un punto de partida mejor para este tipo de análisis.THE PHYSICS ARXIV BLOG
Una de las frases más utilizadas en relación con la web social es el análisis de sentimientos. Esta es la capacidad de determinar la opinión o estado mental de una persona analizando las palabras que usan en Twitter, Facebook o cualquier otro medio.
Este método promete muchas cosas: la capacidad para medir el grado de satisfacción con los políticos, las películas y los productos; la capacidad de manejar mejor las relaciones con los clientes; la capacidad de crear diálogo para juegos basados en las emociones; la capacidad de medir el flujo de la emoción en las novelas, y mucho más.
La idea es automatizar completamente el proceso, analizando la avalancha de palabras producidas por los sitios webs sociales usando técnicas avanzadas de minado de datos para poder medir el sentimiento a gran escala.
Pero todo esto depende de nuestro grado de comprensión de la emoción y polaridad (ya sea positiva o negativa) que la gente asocia con cada palabra o combinación de palabras.
Saif Mohammad y Peter Turney del Consejo Nacional de Investigación de Canadá en Ottawa han desvelado una enorme base de datos de palabras con las emociones y polaridad asociadas a ellas, que han creado de una forma rápida y barata usando el sitio web decrowdsourcing de Amazon Mechanical Turk. Afirman que este mecanismo de crowdsourcingsirve para aumentar el tamaño y la calidad de la base de datos de forma fácil y rápida.
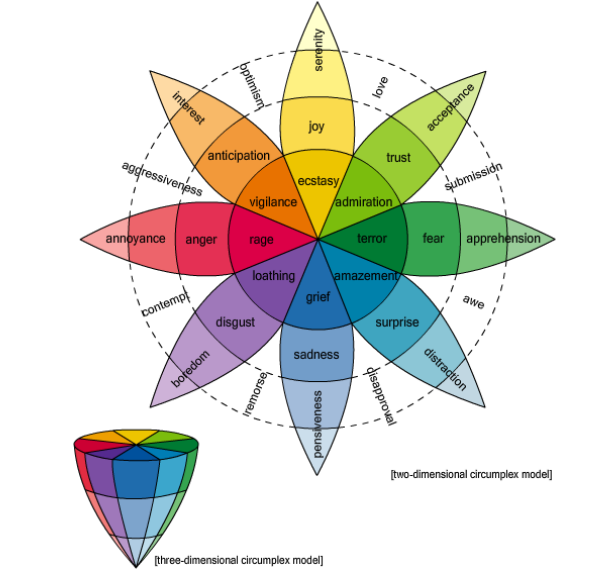
La mayoría de los psicólogos creen que hay seis emociones básicas -alegría, tristeza, ira, miedo, asco y sorpresa- o un máximo de ocho si se incluyen la confianza y la expectación. Así que la tarea de cualquier léxico de palabras y emociones es establecer con qué fuerza se asocia una palabra a cada una de estas emociones.
Una forma de hacerlo es usar un pequeño grupo de expertos para que asocien emociones con series de palabras. Una de las bases de datos más famosa, creada en la década de 1960, y conocida como la base de datos de General Inquirer, tiene más de 11.000 palabras etiquetadas con 182 etiquetas distintas, incluyendo algunas de las emociones que los psicólogos consideran las más básicas.
Una base de datos más moderna es el Léxico WordNet Affect, que tiene unos cientos de palabras etiquetadas así. Este léxico contó con un pequeño grupo de expertos para que etiquetaran manualmente una serie de palabras "semilla" con las emociones básicas. El tamaño de la base de datos aumentó de forma drástica al asociar automáticamente las mismas emociones con todos los sinónimos de estas palabras.
Uno de los problemas derivados de estos métodos es el tiempo que lleva recopilar una gran base de datos, así que Mohammad y Turney probaron con un enfoque ligeramente distinto.
Estos investigadores seleccionaron unas 10.000 palabras de un tesauro existente y de los léxicos descritos anteriormente, y crearon una serie de cinco preguntas sobre cada palabra que revelarían las emociones y polaridad asociados con ella. Esto supone más de 50.000 preguntas.
A continuación hicieron estas preguntas a más de 2.000 personas o Turcos, en el sitio web de Amazon Mechanical Turk, pagando 4 centavos por cada serie de preguntas respondidas correctamente.
El resultado es un léxico completo de palabras-emociones para más de 10.000 palabras o frases de dos palabras que han bautizado EmoLex.
Un factor importante de esta investigación es la calidad de las respuestas que proporciona elcrowdsourcing. Puede ser que algunos Turcos contesten al azar o incluyan respuestas erróneas a propósito.
Mohammad y Turney abordaron este problema insertando preguntas en el test que sirven para evaluar si el Turco está contestando bien o no. Si no, todos los datos de esa persona se ignoran.
Han probado la calidad de su base de datos comparándola con bases anteriores creadas por expertos y afirman que sale bien parada. "Comparamos un subconjunto de nuestro léxico con los datos estándar existentes para demostrar que las anotaciones obtenidas son de gran calidad", afirman.
Este enfoque tiene mucho potencial para el futuro. Mohammad y Turney afirman que debería ser relativamente fácil aumentar el tamaño de la base de datos y que la misma técnica se puede adaptar para crear léxicos parecidos en otros idiomas. Y todo ello se puede hacer por muy poco dinero, los investigadores solo gastaron 2.100 dólares (unos 1.600 euros) en Mechanical Turk para este trabajo.
La conclusión final es que el análisis de sentimientos solo será tan bueno como la base de datos de la que depende. Con EmoLex, los analistas tienen una nueva herramienta para su caja de trucos. MIT
Ref: arxiv.org/abs/1308.6297: Crowdsourcing un Léxico de Asociación de Palabras y Emociones


No hay comentarios:
Publicar un comentario